この章ではHTMLを理解する上で必要な概念を、HTMLのメタ言語であるSGML(Standard Generalized Markup Language)を通して説明しようとしています。
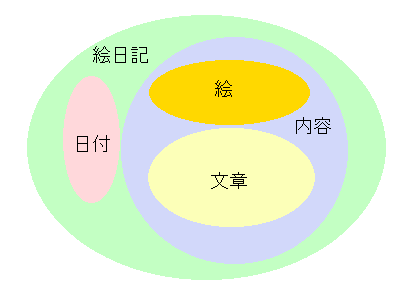
唐突ですが、『えにっき』を思い出してください。
あなたが小学校の先生で、クラスの子供たちに絵日記の宿題を出したとします。
絵日記用の紙を配り、「これに書いてきてください」というのが普通でしょうか。
こうしておけば、クラスの絵日記集としてまとめるにしても、後から読み返すにしても書き方がそろって
いて便利です。
しかし、うっかり絵日記用紙の準備を忘れてしまったら、あなたは黒板に以下のよう
な図を書いて子供達に絵日記の書き方を説明することになるでしょう。
「まず、絵日記には必ず日付を入れて下さい」
「それから、内容です」
「内容の中には、絵と、文章を書いて下さい」
このように絵日記の書き方を定義することによって、絵日記用紙を配るのと同じような効果が得ら れるでしょう。
ところで、このような定型の文書(ここでは絵日記)を定義することを、
文書型定義[document type definition] (DTD)といいます。
また、文書を構成している単位(絵、文章、日付、内容など)を『
要素(element)』と呼びます。これら要素の関係は、ある要素は他の要素に含まれるという内包関係
としてあらわされています。これを内容モデルと言います。
そして、
「後から誰が見ても分かるようにように、どこからどこまでが日付で、どこからどこまでが文章か、
しるしを付けておいてね」と、頼みます。
そして文書型定義にそったしるし付けを、マークアップといいます。
先の絵日記を例にとれば、以下のように表されるかも知れません。
マークアップの標しとして、< >という記号使っています。
<要素名>〜</要素名>と表される部分が、その要素であるということにしています。
<絵日記> <日付>12月24日</日付> <天気>雪</天気> <内容> <絵> クリスマスの絵 </絵>
<文章>
きょうはクリスマスイブ、みんなでクリスマスケーキを食べた。 とても美味しかった。 夜、サンタさんがきて、プレゼントをくつしたに入れてくれた。 サンタさんありがとう。 </文章> </内容> </絵日記>
余計な手間で子供達はぶうぶう言うでしょうが、電子文書をつくる場合にはこの方式は特に有用です。
このようにマークアップされた文書は、プログラムさえあれば、絵日記集としてひとつの形に
まとめることはもちろん、文章だけを集めた文集もできるし、画集にもなります。
後から有効に文書を活用できるというわけです。また、マークアップの方法を一般化しておけば、
さまざまな環境で利用することもできます。
このように記号を使って、定型の文書を処理しようというのがマークアップの考え方です。 定型の文書の定義や、その文書のマークアップの約束事を記述する方法として、 SGML(Standard Generalized Markup Language:標準汎用マークアップ言語)という国際規格があります。
この絵日記文書も、さまざまな約束事(どのような文字や記号を使うかなどの基本的 なところから、文書の構造の定義、文書を構成する要素の内包関係、要素が持つ特性など)を、 SGMLによってきちんと記述できます。そしてこの記述された約束に従ってマークアップされた文書が 『絵日記文書』としてさまざまな形で利用できるようになるわけです。
さてこれはどのように使われるのでしょうか。
マークアップされた電子文書を配布しようとする側は、文書の特徴をがよく伝えられるように、
マークアップに関するさまざまな約束事を決め、それをSGMLで記述します。
その記述を、その約束にそってマークアップされた文書に添付して配布するわけです。
配布された側は、SGMLを解釈できるプログラム
によって、その文書の構造を解釈し、再利用できるというわけです。
実際には、マークアップの約束事を先に公開しておき、それに対応したアプリケーションを用意 しておき、後から『定型文書』だけを配布するというのが一般的かも知れません。
先の章の『絵日記文書』と同じように、HTML(HyperText Markup Language)文書も、 SGMLを使ってマークアップのさまざまな約束事が記述され、その約束に従ってマークアップされた 文書です。このようにSGMLを使った一連の約束やその約束に従ってマークアップされた文書を、 SGML応用(アプリケーション)と言います。そして、HTMLはWWWで情報を交換する手段として もっとも使われているSGML応用です。
ところで、HTMLといっても幾つもの種類があります。SGMLにそって定義された数だけ存在する わけです。また、もしあなたがSGMLで独自の文書型定義(DTD)を書けば、新しい文書型を作ること もできます。と言ってもそれを利用するには文書の構造を解釈して、表現するアプリケーション が必要なわけですが。
W3C(World Wide Web Consortium)というWWWの規格を作っている団体があります。 そのサイトにおいて、SGMLによって記述されたさまざまなHTMLの文書型定義(DTD)見ることができます。
これからのHTMLについての話は、W3Cが勧告した最新のバージョンである HTML4.0のDTDに基づいています。
さてHTMLで書かれた文書はどんな構造を持っているでしょう。 これらの構造は前述したDTDに表されているのですが、これを先程の絵日記の図に似せて描いてみます。
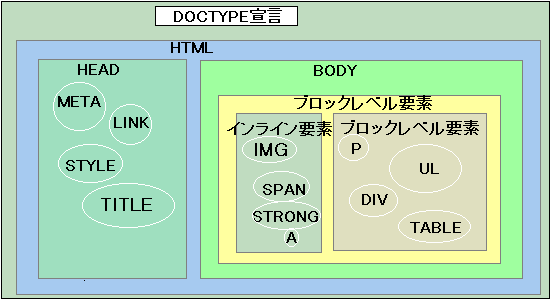
上の図を見るとHTML4.0の文書は以下のような構造を持つのが分かります。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN"
http://www.w3.org/TR/REC-html40/strict.dtd">
<html>
<head>
<meta HTTP-EQUIV="Content-Type" CONTENT="text/html; CHARSET=Shift_JIS">
<title>サンプル</title>
</head>
<body>
<p>こんにちは</p>
</body>
</html>
三行目以下の< >の部分は、マークアップのための記号でタグと呼ばれています。 これらの記号を使って文書をマークアップしています。
内容を<要素名>(開始タグと呼びます)と</要素名>(終了タグと呼びます)の二つのタグの間に挟んで、その部分の内容がどんな要素なのかを表します。
"< >"に書かれている要素名や属性を示すための文字はブラウザでは表示されず、 開始タグを終了タグに挟まれた内容だけが表示されます。
1行目から2行目にかけての部分が『DOCTYPE宣言』といってSGMLによる『文書型宣言』です。
この文書がどういった文書であるかを宣言するものです。
SGMLによってどんな風に記述されているか、ちょっと解読?してみます。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN"
"http://www.w3.org/TR/REC-html40/strict.dtd">
「最小表記は,その最小データの中のRSを無視し,2個以上連続するRE及びSPACE (先頭及び末尾に位置する場合を除く。)を1個のSPACEに置換した上で解釈―JIS X 4151から引用」
通して要約すると以下のような意味になります。
「この文書はHTML文書であり、 その文書型定義(DTD)は未登録所有者『W3C』によって『HTML 4.0』として英語で公開され入手可能である。 その場所は『http://www.w3.org/TR/REC-html40/strict.dtd』である。」
SGMLではこのように、区切りの記号や語句の並びの順番、語句の種類などを決めているわけです。
例えば文書型宣言をする場合は、マーク宣言開始の標し『<!』で始まり、それに続けて『DOCTYPE』と書き、区切りを入れ、
文書型名を入れ、区切り記号の後に外部識別子を記述する、外部識別子というのは・・・・というような約束を決めています。
DOCTYPE宣言について
いったいどんな文書なのかをはっきりさせるため(ひょっとしたら、『ENIKKI文書』かも知れないものね)、
いちばん最初に「この文書はHTML4.0の文書だよ」と宣言しなければなりません。
そのあとにHTML4.0のDTDに従った方法でマークアップされた文書を書いていきます。
この部分を記述しなくとも、ブラウザはその内容をちゃんと表示してくれます。
というより、ブラウザは解釈可能なタグだけを解釈し、この宣言部を読み飛ばしてしまうのかも知れません。
つまり書いても書かなくても一緒のようなものですが、
正式には書くべきものです。
自分がどのバージョンのHTML文書を書いているかも意識できますから
HTML4.0には現在三種類のDTDが存在しています。 その違いを文書型宣言でしなければなりません。
Default DTD: 既定の(厳密な)DTD
http://www.w3.org/TR/REC-html40/strict.dtd
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN"
"http://www.w3.org/TR/REC-html40/strict.dtd">
Transitional DTD: 移行期間用の(緩やかな)DTD
http://www.w3.org/TR/REC-html40/loose.dtd
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"
"http://www.w3.org/TR/REC-html40/loose.dtd">
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Frameset//EN"
"http://www.w3.org/TR/REC-html40/frameset.dtd">
HTML4.0の仕様書
なんかこの部分はよくわからないぞ、または、違うんでないの?のご指摘、このページの感想、など何でも書き込んでくださいね。 一緒に悩みましょう。
<要素名>を開始タグ、</要素名>を終了タグと
言います。
そして開始タグと終了タグに挟まれた部分の内容ががその要素の特質を持ちます。
開始タグにはその要素が持つことのできる属性を付け加えることができます。
例えば、画像を表示させるIMG要素には、その画像ソースがどこにあるのかというSRC属性や、
画像が表示できない環境での代替えのテキスト文を用意するためのALT属性があります。
<IMG SRC="sample.gif" ALT="サンプルの画像">
タグの中に記述される要素名や属性は大文字・小文字の区別はありません。 例えば、ALT属性は、Alt、alt、ALT、aLtとどのように書いてもすべてALT属性として解釈されますが、 現実には大文字・小文字のどちらかに揃えた方がいいですね。
要素は属性を持つことができます。持つことのできる属性の種類はDTDによって決められています。
属性に割り付けられた値を属性値と言います。
属性値は『 " " 』で囲みます。ただし、使われている文字がアルファベットの
『 a〜z、A〜Z 』及びハイフン『 - 』ピリオド『 . 』だけの時は省略可能です。
以下のように表記されます。
ところで、英文の処理では空白文字はこの通り処理されますが、日本語文の場合は ちょっと異なった処理になります。それは日本語が語同士の間の空白が無い言葉のためです。 改行文字を空白として認識するのは英文では必要な機能ですが、日本語の処理では無視されます。
開始タグ直後の改行及び終了タグ直前の改行は無視されます。